Export BigQuery data to Google Firestore & GTM Server


The recent addition of the Firestore Lookup variable in GTM Server opens up a whole new world of possibilities in terms of data enrichment. But how to get data into the Firestore database? This tutorial will show you how to load data from BigQuery into Firestore (including code samples).
Contents
- Set up a Google Workflow that exports BigQuery data to a Storage Bucket as JSON.
- Set up a Google Cloud Function that uploads the JSON file to Google Firestore.
- Connect Firestore to Google Tag Manager Server and use the Firestore Lookup Variable
Google Tag Manager Server & Firestore
The release of the Firestore Lookup and asynchronous variables within GTM Server variables opens up a whole new world of possibilities.
By using the Firestore Lookup variable (or the asynchronous variable to lookup data from some other system) one could think of the following use cases:
- Enrich product data / transactions (e.g. adding margins or product attributes)
- Enrich user data (e.g. adding user properties, segments, CLV scores)
- User-ID enrichment / identity stitching (retrieve alternative identifiers)
The Firestore API that powers the Firestore Lookup variable, can also be leveraged to write data to Firestore. Use cases:
- A persistent storage system (e.g. storing user-level data over different events)
- Enrich user data (e.g. adding user properties, segments, CLV scores)
- And much more
Many clients I work for, store the necesarry data for the use cases mentioned above in Google BigQuery (think of single user profiles or product feeds). However, BigQuery is not suitable to connect directly to GTM Server.
A while ago I wrote an comparable article explaining how to connect a Redis cache to GTM Server. However the Firestore method seems the way to go now (although the Redis / GTM Server connection can be optimized using asyncrhoniys variables)
BigQuery vs. Firestore
BigQuery is meant as an analytics database, not as a database that can perform a lot of reads and writes in low latency environments. But what databases do?
The following graph is a nice representation of the different databases and use cases. (of course biased to the options available in the Google Cloud)
 Google Cloud database options. Image by thecloudgirl.dev
Google Cloud database options. Image by thecloudgirl.dev
There a multiple contenders for our use case (think of Redis / Memcache used in a related article), but in this case we'll opt for Firestore.
The solution - Google Workflows!
The solution we've build and are sharing in this article leverages a Google Worfklow and a Google Cloud Function.
Google Workflow enables you to set up an automation with just a "simple" .yaml file (also see code below). The Google Workflow will:
- Export the specified query to a new BigQuery table
- Export the table to a Storage Bucket in JSON format
- Creates a message in a Google Pub/Sub topic (holding the configuration for the Cloud Function to run like the bucket name and project-ID)
Lastly, a Google Cloud Function will trigger, opens the JSON export in the Storage Bucket and loops the rows into the Firestore database.
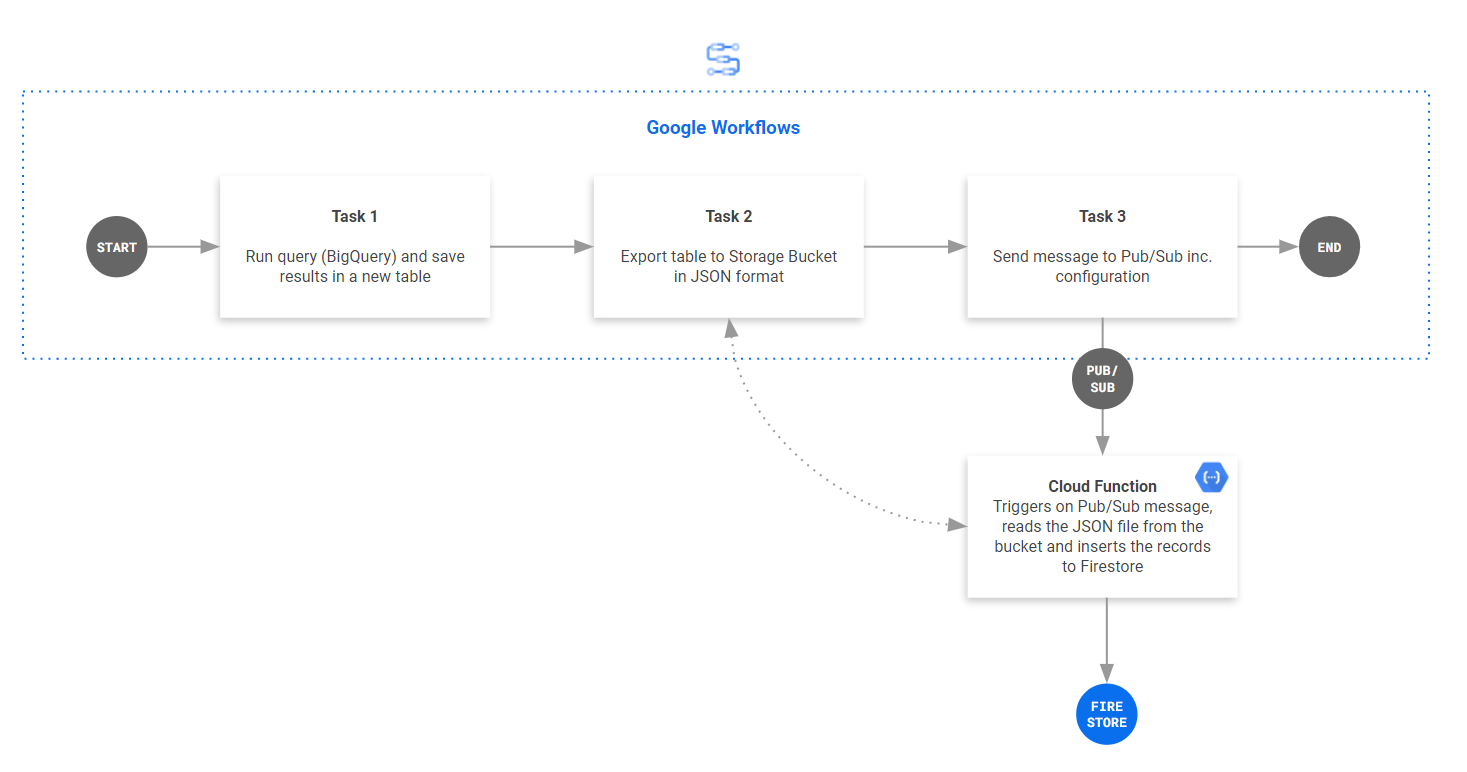
Read more about Google Workflows in my other tutorial.
Prerequisites
So let's start!
Before proceeding, make sure you have:
- An active Google Cloud Project
- Some data within Google BigQuery, ready to send Firestore
- A query that fetches the data you want to send to Firestore (and think of a unique key you want to match with event data in GTM Server)
- A Google Cloud Storage bucket (to store the BigQuery exports)
And don't forget to enable the following services in your GCP project (and have some basic knowledge about the services):
- Enable Google Workflows
- Enable Google Cloud Functions
- Enable Google Pub/Sub
Step 1: Create the Google Cloud Function
First step, create a Cloud Function that triggers on a Pub/Sub topic. Also create the Pub/Sub topic (can be done directly when creating the Cloud Function).
- Environment: 1st gen
- Trigger type: Cloud Pub/Sub
- Memory Allocated: 1GB (depends on the amount of data you want to process, so adjust accordingly).
- Timeout: Depends on the file size you want to process (see limits). For files that are not that large, you could start with the default 60 seconds.
- Runtime: Node.js 16
- Attach a Service Account that has access to the Google Cloud Bucket + Firestore + Pub/Sub
Configure the following roles for the Service Account that is running the the Cloud Function (and is also added to the project where Firestore is enabled)
- Storage Admin
- Cloud Datastore User
- Pub/Sub Publisher
Copy paste the JS code below (also available in the GitHub repo)
You don't have to adjust or configure anything in the scripts itself. The Google Workflow will pass the configuration settings (like the bucket / path of the JSON export) in the Pub/Sub message.
package.json
1{
2 "name": "gcf-cloudstorage-to-firestore",
3 "version": "1.0.0",
4 "dependencies": {
5 "@google-cloud/storage": "^5.20.3",
6 "firebase-admin": "^10.2.0",
7 "split": "^1.0.1"
8 }
9}
index.js
1'use strict';
2
3const admin = require('firebase-admin');
4const {Storage} = require('@google-cloud/storage');
5const split = require('split');
6const { pipeline } = require('stream/promises');
7
8// Upload functioin
9async function jsontoFirestore(file, firestoreKey, firestoreCollection) {
10
11 let keysWritten = 0;
12
13 return new Promise(resolve => {
14 file.createReadStream()
15 .on('error', error => reject(error))
16 .on('response', (response) => {
17 // connection to GCS opened
18 }).pipe(split())
19 .on('data', async record => {
20 if (!record || record === "") return;
21 keysWritten++;
22
23 const data = JSON.parse(record);
24 const key = data[firestoreKey].replace(/[/]|\./g, '');
25
26 try {
27 await admin.firestore().collection(firestoreCollection).doc(key).set(data)
28 } catch(e) {
29 console.log(`Error setting document: ${e}`);
30 }
31 })
32 .on('end', () => {
33 console.log(`Successfully written ${keysWritten} keys to Firestore.`);
34 })
35 .on('error', error => reject(error));
36 });
37}
38
39/**
40 * Triggered from a Pub/Sub message.
41 *
42 * @param {!Object} event Event payload.
43 * @param {!Object} context Metadata for the event.
44 */
45exports.loadCloudStorageToFirestore = async(event, context) => {
46
47 const pubSubMessage = event.data ? Buffer.from(event.data, 'base64').toString(): '{}';
48 const config = JSON.parse(pubSubMessage);
49
50 console.log(config)
51
52 if (typeof config.projectId != 'undefined') {
53
54 const projectId = config.projectId;
55 const bucketName = config.bucketName;
56 const bucketPath = config.bucketPath;
57 const firestoreCollection = config.firestoreCollection;
58 const firestoreKey = config.firestoreKey;
59
60 console.log(`Initiated new import to Firebase: gs://${bucketName}/${bucketPath}`)
61
62 // Init Firebase
63 if (admin.apps.length === 0) {
64 admin.initializeApp({ projectId: projectId })
65 }
66
67 // Init Storage
68 const storage = new Storage()
69 const bucket = storage.bucket(bucketName);
70 const file = bucket.file(bucketPath);
71
72 try {
73
74 // TO-DO: Remove old records
75
76 // Read file and send to Firestore
77 await jsontoFirestore(file, firestoreKey, firestoreCollection);
78
79
80 } catch(e) {
81 console.log(`Error importing ${bucketPath} to Firestore: ${e}`);
82 }
83 }
84
85};
Some parts taken from this Cloud Function.
Step 2: Create the Google Workflow
Create a new Google Workflow and make sure the Service Account you assigned to the Workflow has access to the following services:
- Google BigQuery (BigQuery Data Editor + BigQuery Job User)
- Google Storage (Storage Admin)
- Google Cloud Scheduler (to regularly execute the Workflow)
Copy / paste the code from below (or from this GitHub repository
This time, you do need to add your configuration values (like
project_idorgcs_bucket).
The GCP console will render a visual representation of your Workflow and should look something like this:

workflow-bigquery-to-cloudstorage.yaml
1- init:
2 assign:
3 - project_id: "<your-project-id>"
4 - bq_dataset_export: "<your-bq-dataset-for-export-table>"
5 - bq_table_export: "<your-bq-tablename-for-export-table>"
6 - bq_query: >
7 select
8 user_id,
9 device_first,
10 channel_grouping_first
11 from
12 `stacktonic-cloud.st_core.dim_customer`
13 - gcs_bucket: "<your-export-bucket>"
14 - gcs_filepath: "firestore-export/firestore-export.json"
15 - pubsub_topic: "<your-pubsub-topic-name>"
16 - pubsub_message: {
17 "projectId": "<your-firestore-project-id>",
18 "bucketName": "<your-export-bucket>",
19 "bucketPath": "firestore-export/firestore-export.json",
20 "firestoreCollection": "<your-firestore-collection>",
21 "firestoreKey": "<your-key-to-use-as-firestore-document-id>"
22 }
23- bigquery-create-export-table:
24 call: googleapis.bigquery.v2.jobs.insert
25 args:
26 projectId: ${project_id}
27 body:
28 configuration:
29 query:
30 query: ${bq_query}
31 destinationTable:
32 projectId: ${project_id}
33 datasetId: ${bq_dataset_export}
34 tableId: ${bq_table_export}
35 create_disposition: "CREATE_IF_NEEDED"
36 write_disposition: "WRITE_TRUNCATE"
37 allowLargeResults: true
38 useLegacySql: false
39
40- bigquery-table-to-gcs:
41 call: googleapis.bigquery.v2.jobs.insert
42 args:
43 projectId: ${project_id}
44 body:
45 configuration:
46 extract:
47 compression: NONE
48 destinationFormat: "NEWLINE_DELIMITED_JSON"
49 destinationUris: ['${"gs://" + gcs_bucket + "/" + gcs_filepath}']
50 sourceTable:
51 projectId: ${project_id}
52 datasetId: ${bq_dataset_export}
53 tableId: ${bq_table_export}
54- publish_message_to_pubsub:
55 call: googleapis.pubsub.v1.projects.topics.publish
56 args:
57 topic: ${"projects/" + project_id + "/topics/" + pubsub_topic}
58 body:
59 messages:
60 - data: ${base64.encode(json.encode(pubsub_message))}Now run the Google Workflow!
The workflow should export the BigQuery query results (yes!) to Cloudstorage and load it into Firestore:

Step 3: Connect GTM Server with Firestore
The last step, make sure the GTM environment can connect with the Firebase database. Simo Ahava already wrote a great article about Firestore and GTM Server, so check out that article.
Some remarks:
- Make sure you set up Firestore in Native mode (can't be undone)
- When you run GTM Server in App Engine, make sure the Service Account that runs App Engine (probably App Engine default service account) has access to Firestore (Datastore User).
- If not in the same project, add the service account that runs App Engine to the project where Firestore lives.
Limits & cost
Some last considerations:
Limits
This setup is using full loads:
- Only new records are added or existing records are updated (so old records are not deleted).
- This process can be optimized by using delta’s (for example set up a process in BigQuery calculating the daily delta’s) or deleting all the records in the Firestore collection first.
Possible issues with large datasets:
- Google Cloud Functions timeout limit (configurable, but a maximum runtime of 9 minutes)
- Google Cloud Function memory limit (although files from Cloud Storage are not fully loaded into memory but processed streaming)
Costs
Google Workflows and Cloud Functions are serverless. Likely these will not incur a lot of costs since the Workfow and Function probably won't be executed a lot. Firestore heavily depends on volume + there is also a free tier. Check the official pricing overview for the full overview.



